
The Prompter #008
Nov 14 - Nov 23

welcome to The Prompter #008!
this is a weekly newsletter by Krea designed to keep you up to date with all the latest advances in the fast-paced field of generative AI.

📰 AI news
Versatile Diffusion

Versatile Diffusion is designed to handle text-to-image, image-to-text, image-variation, and text-variation tasks in a unified way.
The model is based on a multi-flow diffusion pipeline, which is a generalization of the existing single-flow diffusion pipeline.
The paper demonstrates that the Versatile Diffusion model is able to handle all subtasks with competitive quality, and that it can be used for novel applications such as disentanglement of style and semantic, image-text dual-guided generation, etc.
MagicVideo: Efficient Video Generation With Latent Diffusion Models

MagicVideo is an efficient text-to-video generation framework based on latent diffusion models that can produce photorealistic video clips from text descriptions.
The system is 64 times faster than the previous video diffusion model (VDM), and can generate video clips with 256x256 spatial resolution on a single GPU card.
MagicVideo can generate both realistic video content and imaginary content in a photo-realistic style with a tradeoff in terms of quality and computational cost.
Magic3D: High-Resolution Text-to-3D Content Creation
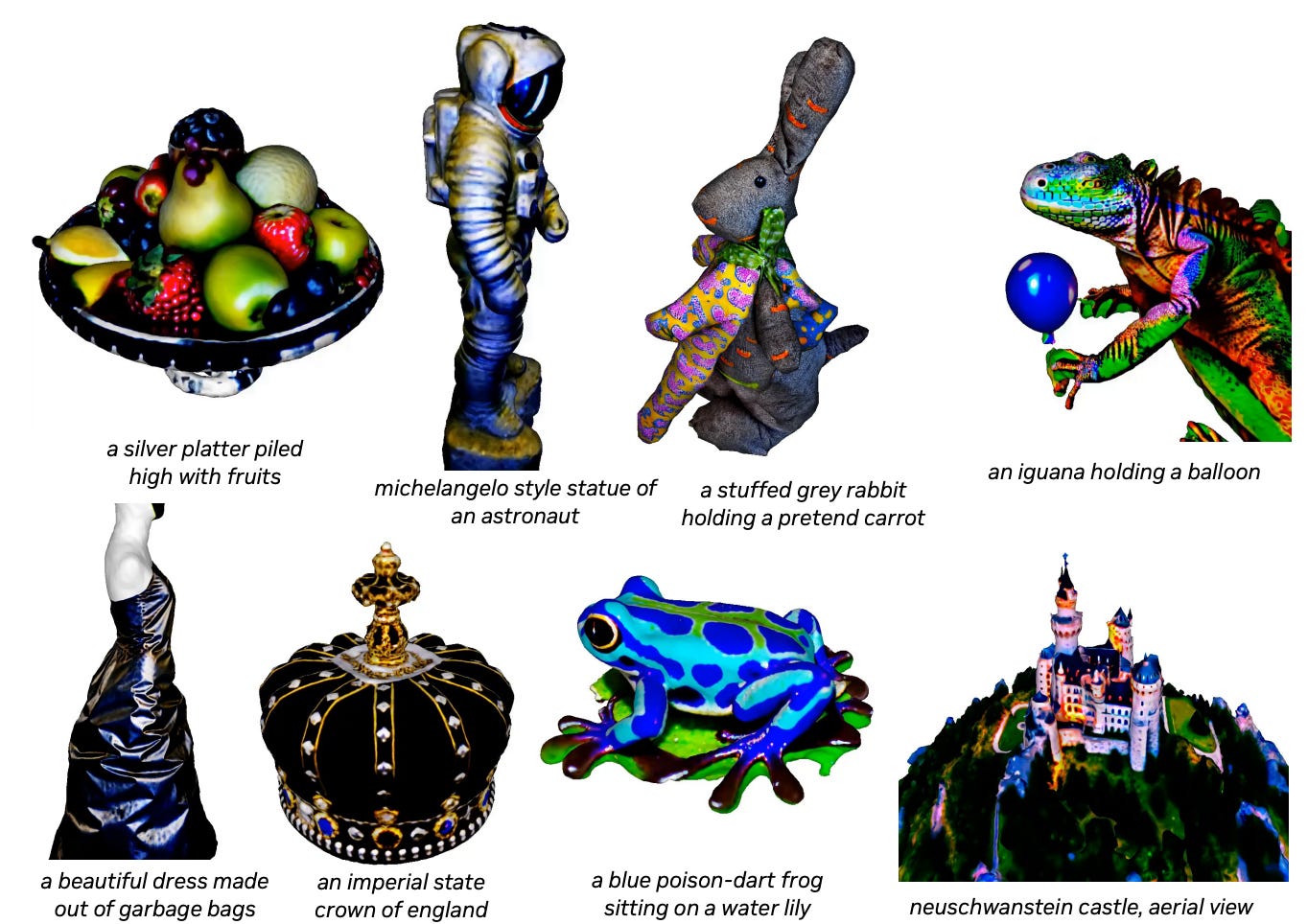
Magic3D can create high quality 3D mesh models 2x faster than the previous best method, DreamFusion.
This model is based on a two-stage optimization framework, which first obtains a coarse model using a low-resolution diffusion prior, and then further optimizes a textured 3D mesh model with an efficient differentiable renderer.
User studies show that 61.7% of people prefer the models generated by Magic3D over those generated by DreamFusion.
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models

Diffusion models have previously been used to generate raster images of diverse objects and scenes, but this study shows that they can also be used to generate vector graphics of similar quality without needing access to large datasets of captioned vector images.
VectorFusion is inspired by recent work on text-to-3D synthesis, and it involves vectorizing a text-to-image diffusion sample and fine-tuning with a Score Distillation Sampling loss.
VectorFusion produces more coherent graphics than prior works based on optimizing CLIP visual embeddings.
🛠️ AI tools
Nomic created an interactive graph to visualize 6M+ Stable Diffusion generations.
With HuggingFace now you can create a DreamBooth model in less than 5 minutes.
New updates from Wand, a new iOS app for AI assisted drawing.
Free Versatile Diffusion Demo at HuggingFace.
Use text to inpaint objects in your images with CLIPSeg.
A new fine-tuned model to generate Emojis is out!

✨ about Krea
We've been working closely with a great group of visual artists on a brand new product - and it's looking good!
Stay tuned for new AI models, fast generations, and an intuitive and visual interface. In the meantime, check out this screenshot of the work-in-progress!
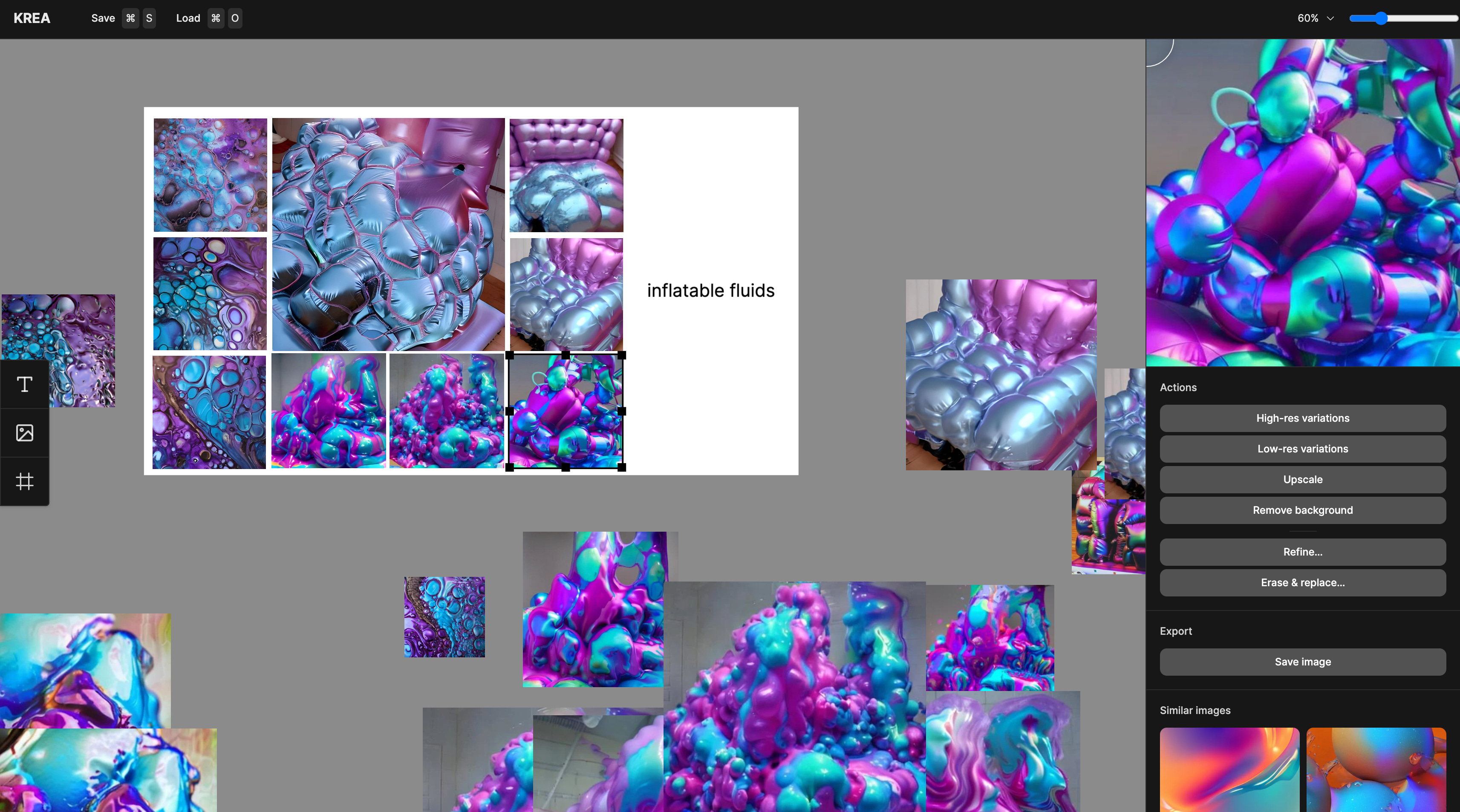
This new interface will be available soon for beta-tester, we’ll share the waitlist soon on our twitter account.